ラノベデータベースを作る 〜OCR〜のつづき。
今回は画像のバリエーションを増やしてみる。
最初のサンプルはこちら。
[caption id=”attachment_131” align=”alignnone” width=”206”] OCRサンプル2。test2.png[/caption]
OCRサンプル2。test2.png[/caption]
コレは縦書きだ。
[caption id=”attachment_132” align=”alignnone” width=”206”] OCRサンプル3。test3.png[/caption]
OCRサンプル3。test3.png[/caption]
これがサッと思いついたちょっと難しそうな漢字。
[bash]
$ tesseract test2.png result -l jpn+eng -psm 5
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
$ cat result.txt
日本語
あいう
ABC
$ tesseract test3.png result -l jpn
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
$ cat result.txt
壱 鬱
[/bash]
縦書きの場合は -psm 5をオプションに入れればいいし、ちょっと難しそうな漢字も難無く読み取れるようだ。
それではこれはどうか。長めの文章だ。
[caption id=”attachment_134” align=”alignnone” width=”300”] OCRサンプル4。長めの文章。[/caption]
OCRサンプル4。長めの文章。[/caption]
[bash]
$ tesseract test4.png result -l jpn
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
$ cat result.txt
手持ちのコ三ックスゃラノべのデ一タべ一スを作りたいと
思った時、 全部手作業で入カするにはだぃ,ぶ厳しい分冒が
ぁるので、 どうせなら` 背表紙が写るょぅに並べて撮影今
各本ごとの領域に切り分け今。cR今タィ トル/著者くらぃ
の情報を得て、 デ一タべ一スに放り込む、 みたいなシステ
ムを作りたぃと思ぅわけだ〟 その準備として、 まずは0cR
で文字が認識出来るかどうか、 取り敢ぇずで触ってみる〟
[/bash]
なんだか惜しいところが沢山ある。これを人間が読む分には別にこれでも良い気もするが、データベースに放り込む内容としてはかなり難がある。最悪、こうやって読み取ったデータを手作業でチェックしていってもいいけれど…
[caption id=”attachment_135” align=”alignnone” width=”300”] OCRサンプル5。サンプル4からの切り抜き。[/caption]
OCRサンプル5。サンプル4からの切り抜き。[/caption]
1行だけ切り抜いてみると、次の通り。
[bash]
$ tesseract test5.png result -l jpn
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
[tea@teaarch ocr_test]$ cat result.txt
ぁるので どうせなら 背表紙が写るょうに並べて撮影今
[/bash]
比較すると、こういう感じだ。
ぁるので、 どうせなら` 背表紙が写るょぅに並べて撮影今 ぁるので` どうせなら` 背表紙が写るょうに並べて撮影今
大差無いっていうか、むしろ悪化している(前後の行がなくなったので、上下の位置関係がわかりにくくなった?)。
次は回転させてみよう。
[caption id=”attachment_136” align=”alignnone” width=”289”]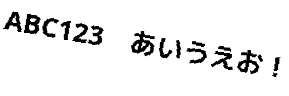 OCRサンプル6。10度回転させた。[/caption]
OCRサンプル6。10度回転させた。[/caption]
[bash]
$ tesseract test6.png result -l jpn+eng
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Empty page!!
Empty page!!
[/bash]
ダメだ。-psmで少し条件を変えてみたけど、7,6,4の時は拾えたけど、あとはやっぱりダメ。文字が少なすぎるか、回転させすぎかな?
[caption id=”attachment_144” align=”alignnone” width=”289”]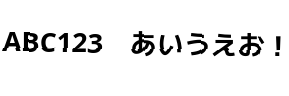 OCRサンプル7。回転量を減らした[/caption]
OCRサンプル7。回転量を減らした[/caption]
[bash]
$ tesseract test7.png result -l jpn+eng -psm 1
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Too few characters. Skipping this page
OSD: Weak margin (0.00) for 10 blob text block, but using orientation anyway: 0
[tea@teaarch ocr_test]$ cat result.txt
ABC123 あいうえお!
[/bash]
殆ど回転してないようにも見えるけど、要はほんの少しの傾きならなんとかなるという事だ。ちなみに-psm 1入れなくても同じ結果になった。オプションよくわからん。
正確に(傾き無く)切り出せる事、読み取りミスをなんとか吸収出来る事、がラノベデータベースにおける必要条件だな。